
Best LLMs for Long-Context & Multimodal Tasks in 2026
Why 2026 Changed Everything
Three structural shifts have redefined what "good enough" looks like, and if you're still picking models the way you did in 2024, you're leaving performance and money on the table.
Context windows went from "large" to "limitless." Llama 4 Scout's 10 million-token window means you can feed an entire software repository, a year of support tickets, or a legal case file into a single prompt. Gemini 3.5 Flash, GPT-5.5, Claude Opus 4.7, and Grok 4.3 all hit 1 million tokens. Long-context is no longer a premium feature — it's a baseline expectation.
Multimodal went from demo to production. The 2026 frontier models don't just read images — they reason across text, images, documents, audio, and video in the same inference call. Gemini 3.5 Flash leads here, but Claude Opus 4.7, GPT-5.5, and Mistral Large 3 are all genuinely capable across modalities. Picking a text-only model for a document or visual workflow is increasingly a mismatch.
Prices collapsed by 40–80% year-over-year. DeepSeek V4 Flash runs at $0.14 per million input tokens. Grok 4.3 at $1.25. Gemini 3.5 Flash at $1.50. The question is no longer "can we afford to use AI?" but "which model gives us the best quality-per-dollar for this specific workload?"
Top Models in 2026 Reviewed
Ratings are based on benchmark data, pricing, real-world production reports, and developer community signals as of June 2026.
OpenAI
GPT-5.5
GPT-5.5 is OpenAI's current frontier release and the default benchmark against which every other model in this guide is measured. Its 1,050,000-token context window, one of the largest among closed US-lab models, supports full reasoning-token budgets, meaning the model can spend additional compute thinking through problems before producing a final answer. Structured outputs, function calling, and native image input are all production-ready and well-documented, making it the lowest-friction choice for teams already in the OpenAI ecosystem. Multi-step data analysis and research synthesis are particular strengths: GPT-5.5 maintains consistency across very long chains of tool calls in ways that earlier models routinely lost track of. Native audio input arrived in April 2026, removing the need for a separate speech-to-text pipeline in voice-agent workflows. The Pro tier at $30 input / $180 output per million tokens is expensive, but for high-stakes tasks where quality variance is the real cost driver, it is often the correct tradeoff.
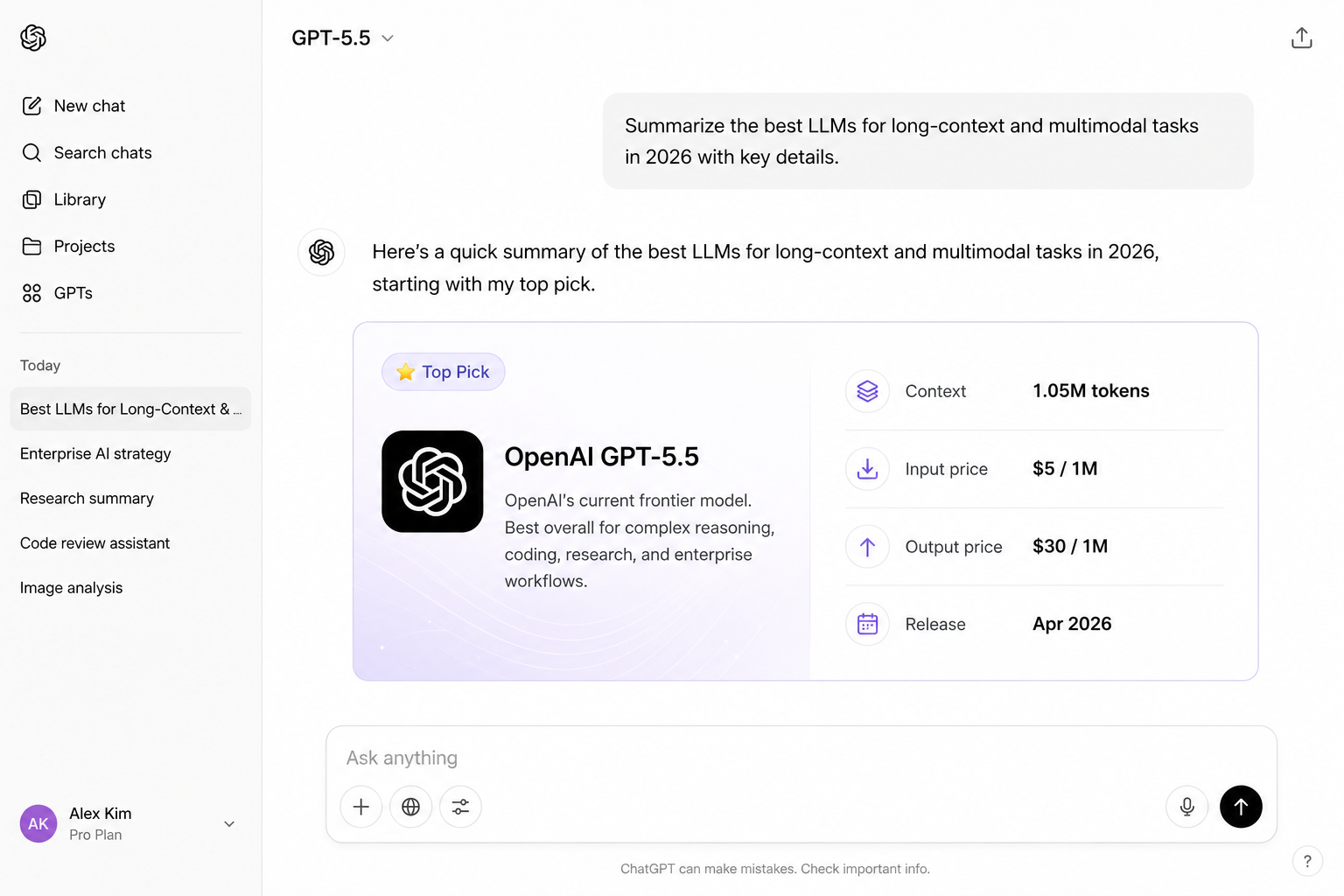
- 1,050,000 token context with reasoning token support
- Structured outputs, function calling, image input
- Strong on multi-step data analysis and research
- GPT-5.5 Pro tier for maximum accuracy at $30/$180
Anthropic
Claude Opus 4.7
Claude Opus 4.7 is Anthropic's previous flagship, and it remains a strong choice for software engineering and structured agentic work even after the release of 4.8. Multi-file codebase analysis and debugging are where it earns its reputation: the model tracks dependencies across large repositories and identifies root causes with a reliability that has made it a default in many production CI pipelines. Its performance across sessions involving 50 or more tool calls is notably stable, Opus 4.7 does not progressively lose the thread of the original task the way some competing models do under extended agentic load. Instruction-following on complex, conditional specifications is excellent, and the model's refusal behavior is well-calibrated for enterprise contexts that need predictable guardrails rather than overly cautious defaults. Multimodal support covers text, image, and document reasoning, making it capable of handling tasks that mix code, documentation screenshots, and structured data in a single session. Teams already running Opus 4.7 in production have little pressure to migrate immediately to 4.8 unless the incremental gains in ambiguous-spec handling or document reasoning are critical to their workflows.
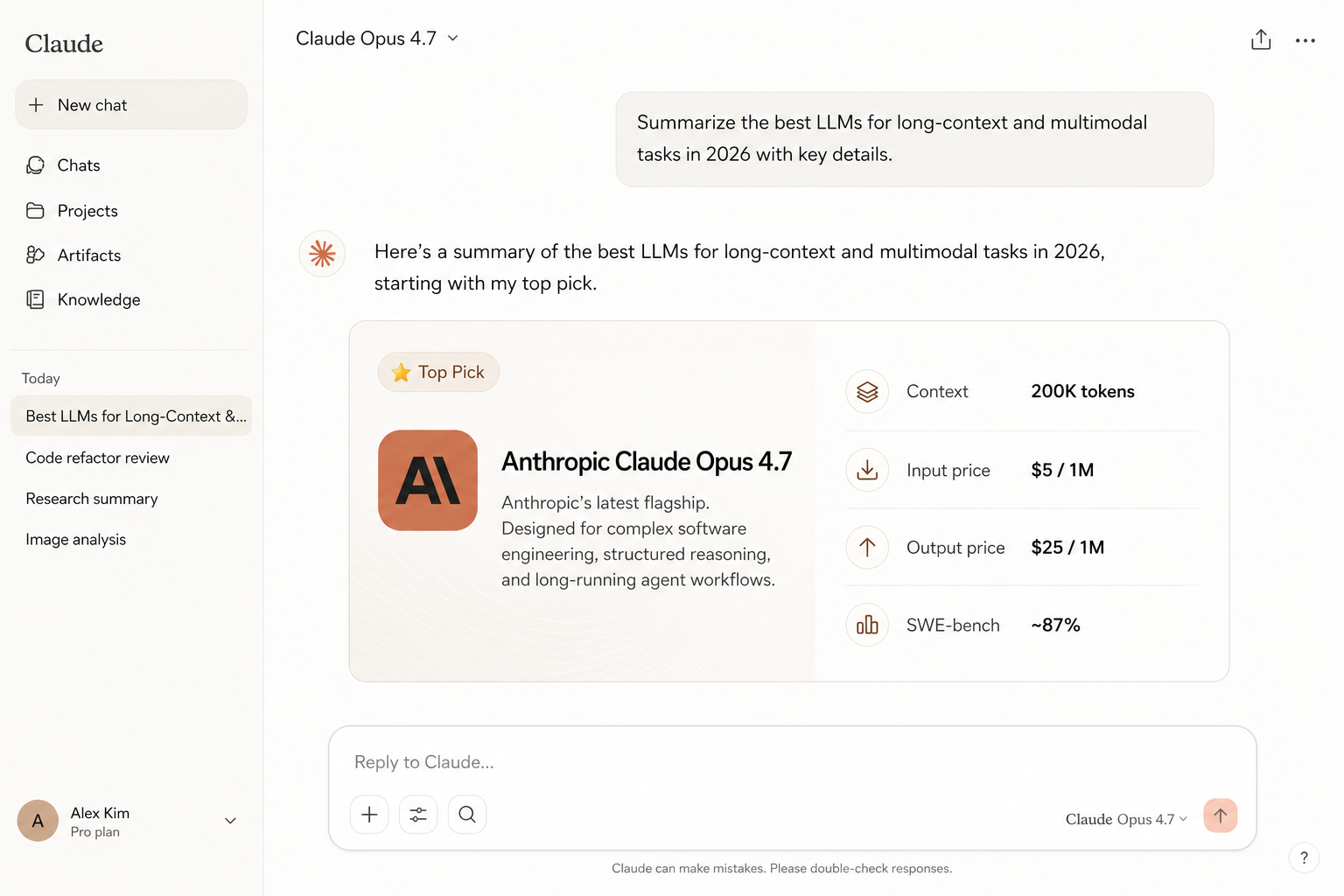
- Best for multi-file codebase analysis and debugging
- Reliable on 50+ tool-call agent sessions
- Strong instruction-following and refusal behavior
- Multimodal: text, image, and document reasoning
Google DeepMind
Gemini 3.5 Flash
Gemini 3.5 Flash sits at the intersection of the two things that matter most in 2026 production pipelines: a genuine 1M-token context window and native multimodal capability across text, images, audio, and video in a single call. At $1.50 input / $9.00 output per million tokens it is significantly cheaper than GPT-5.5 while covering the same context scale, which is a material advantage at the volume that long-document pipelines actually run. Google positions it specifically for agentic execution, meaning the model has been tuned for multi-step tool-calling workflows rather than just passive document summarization, and the benchmark numbers back that positioning.
Video understanding is a notable differentiator: native frame analysis and temporal reasoning happen in a single inference call, eliminating the separate transcription or frame-sampling infrastructure that video-heavy workflows otherwise require. For teams building document intelligence pipelines, multimodal agents, or coding assistants that need to hold large codebases in context, Flash covers the most use cases per dollar of any closed model currently in production. It is our default recommendation for teams that need both scale and breadth without picking a specialist model for every modality.
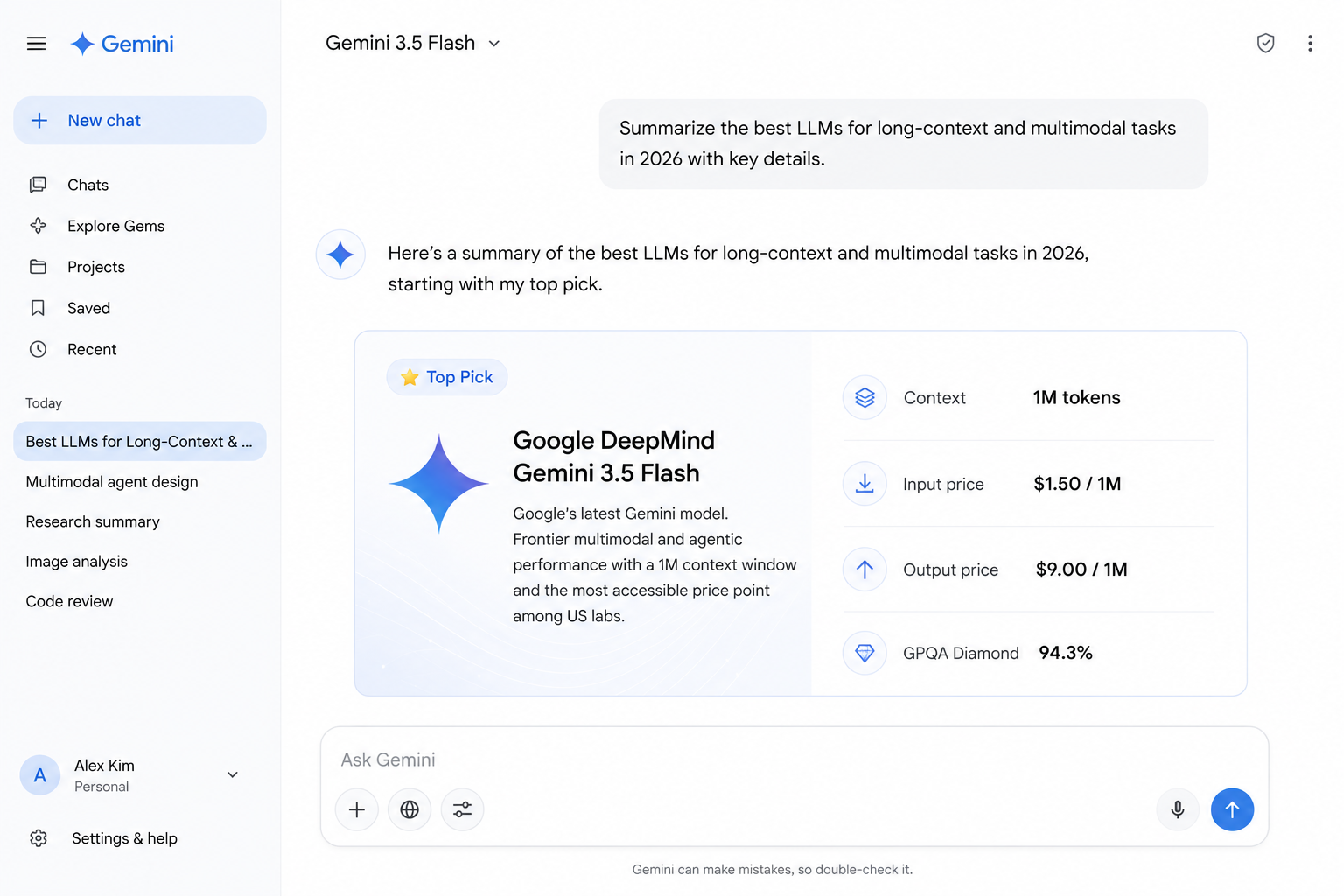
- True 1M-token context — entire codebases in one call
- Native image, audio, and video understanding
- Best-in-class cost-to-capability ratio for US labs
- Strong for agentic tool use and long-horizon tasks
xAI
Grok 4.3
Grok 4.3 is xAI's current flagship and the price outlier in the closed frontier tier: the lowest output cost among comparable US-lab models makes it a serious option for high-volume pipelines where per-token cost compounds quickly. Configurable reasoning depth is a differentiator, you can dial reasoning effort per request rather than paying for maximum thinking on every call, which meaningfully reduces cost for tasks that do not require full chain-of-thought.
The 1M-token context window handles large document or codebase inputs without chunking, and the model's agentic tool calling is solid for workflows that need real-time data access. Live research and trend monitoring are particular strengths, partly because Grok has privileged access to real-time signals from the X platform, giving it an edge over models that rely solely on training data or third-party search tools. For teams that primarily need a fast, affordable frontier model for research tasks and tool-heavy pipelines rather than the highest possible reasoning accuracy, Grok 4.3 is the most cost-effective option in the closed tier. The tradeoff relative to GPT-5.5 or Gemini 3.5 Flash is depth of multimodal capability and instruction-following precision on highly structured enterprise tasks.
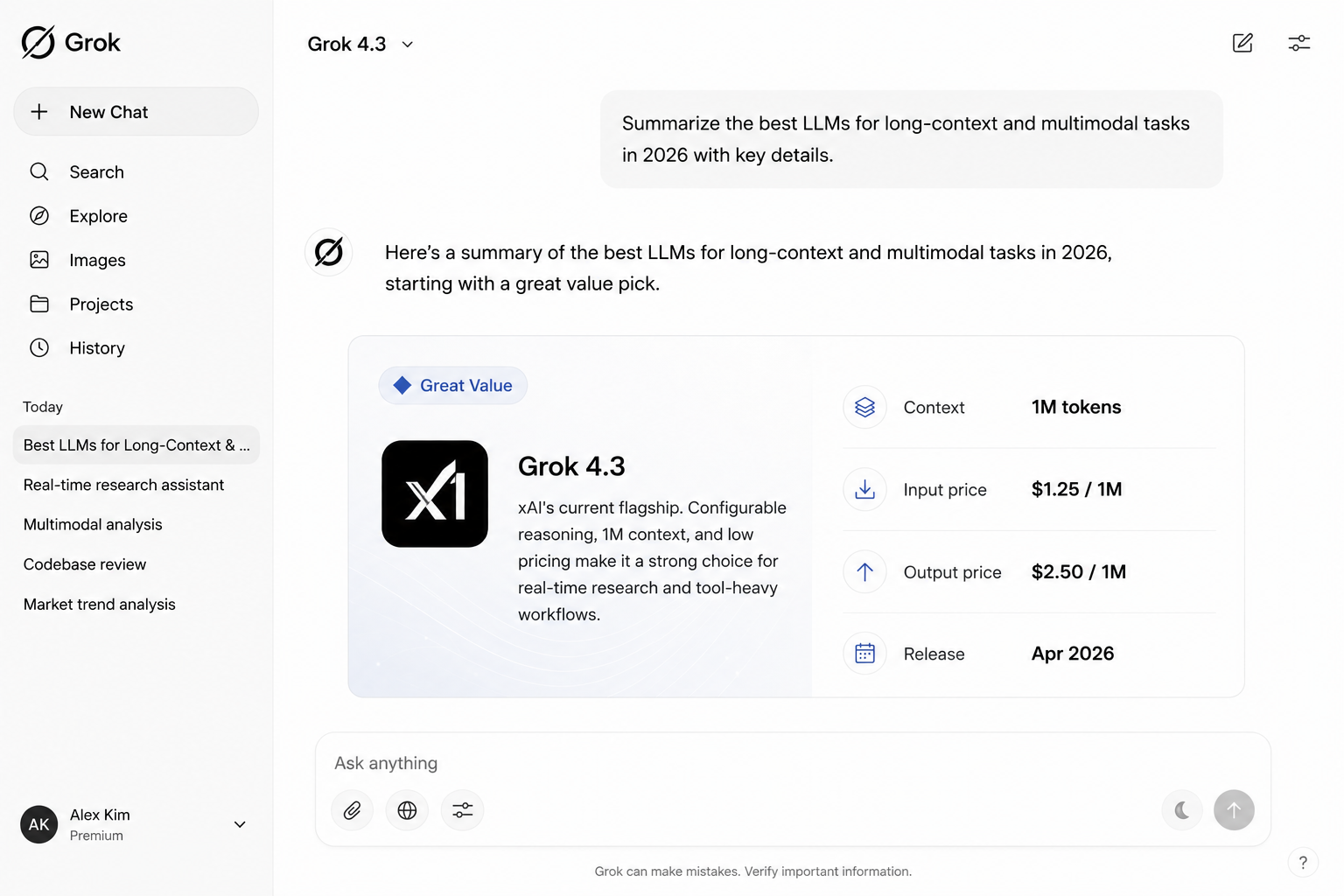
- Lowest output price among frontier closed models
- Configurable reasoning depth per request
- Strong for live research and trend monitoring
- Agentic tool calling and function use
Z.ai / Zhipu
GLM-5.2
GLM-5.2 carries an MIT license, the most permissive in this category, which makes it the most legally uncomplicated open-source model for teams that need to fine-tune, modify, or redistribute without negotiating commercial agreements. Coding and agentic benchmark scores are competitive with models significantly larger, and the MIT license means fine-tuning on proprietary data is straightforward without restrictions that other open-weight licenses impose.
Tool-calling reliability is production-ready for most agent architectures, and multilingual coverage including strong Chinese-language performance gives it an advantage for teams serving international markets. Self-hosted inference cost is low enough that it becomes viable for high-volume pipelines where frontier closed models would be prohibitively expensive. The main consideration is the Chinese-lab origin, which is a non-issue for many teams and a disqualifier for others depending on data-sovereignty requirements. For teams that have assessed that tradeoff and need maximum license freedom, GLM-5.2 is the current best option in the MIT open-weight tier.
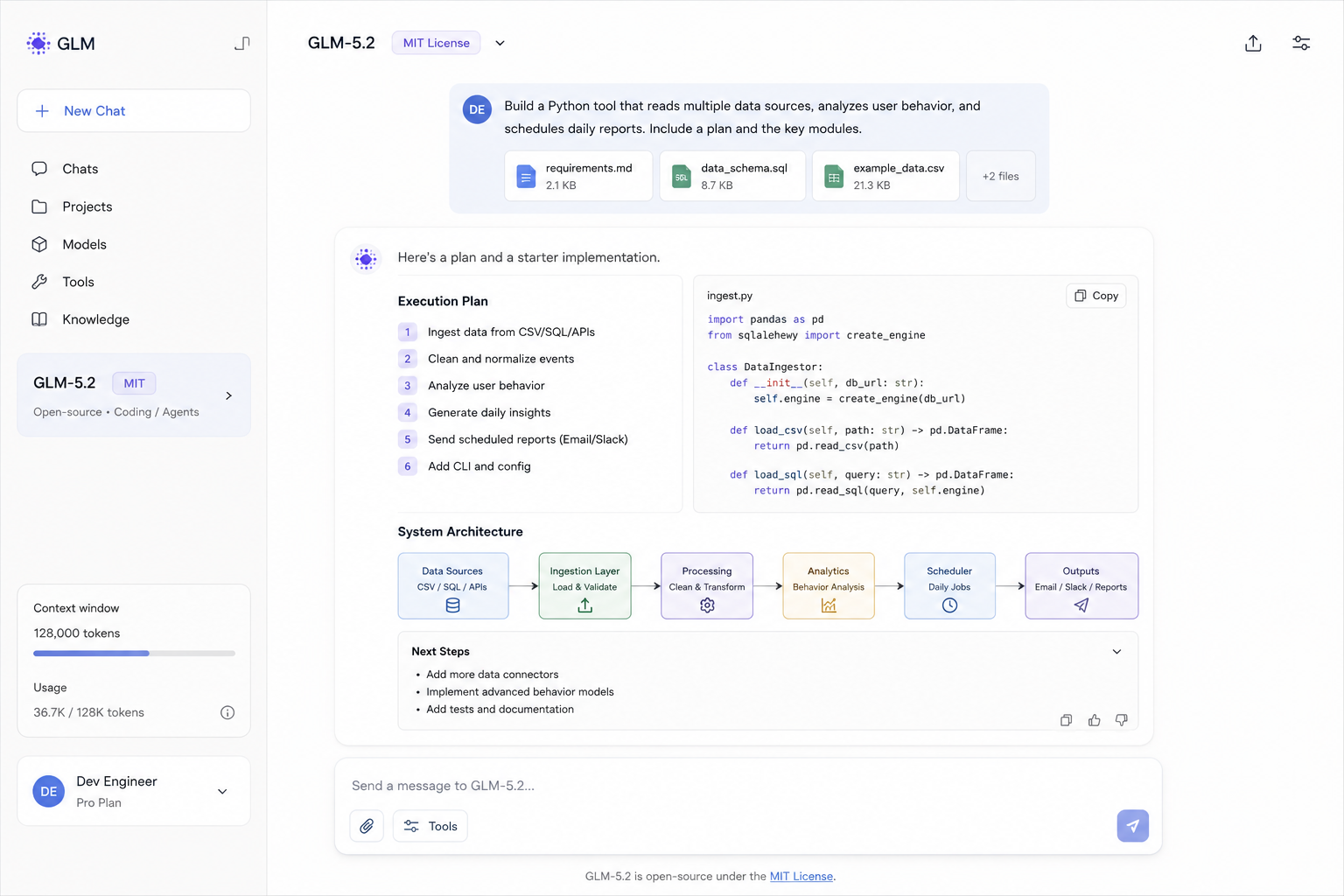
- MIT license — freely fine-tunable and redistributable
- Competitive coding and agentic benchmark scores
- Very low self-hosted inference cost at scale
- Strong multilingual coverage including Chinese
Anthropic
Claude Opus 4.8
Claude Opus 4.8 builds on 4.7's foundation with measurable improvements in the two areas that matter most for production deployments: extended agent session reliability and ambiguous specification handling. Where 4.7 already led the field on multi-tool agentic coherence, 4.8 extends that advantage — developers report fewer task drift incidents in sessions that run past 60 or 80 tool calls, which is the range where most competing models begin losing the original intent. Ambiguous spec interpretation has improved notably: the model makes better decisions about under-specified requirements without requiring explicit disambiguation at every step, which speeds up iteration in software engineering workflows.
Document reasoning is also stronger than 4.7, particularly for PDFs with complex mixed-content layouts, tables, and embedded charts — a common bottleneck in enterprise document intelligence pipelines. The 200K context window is smaller than Gemini 3.5 Flash or GPT-5.5 on paper, but for the use cases where Opus 4.8 excels — reliability-critical agent workflows, structured enterprise tasks, careful document reasoning — window size is rarely the binding constraint. For teams where a single context-handling failure in production is genuinely costly, the reliability premium over any other model currently available justifies the smaller window.
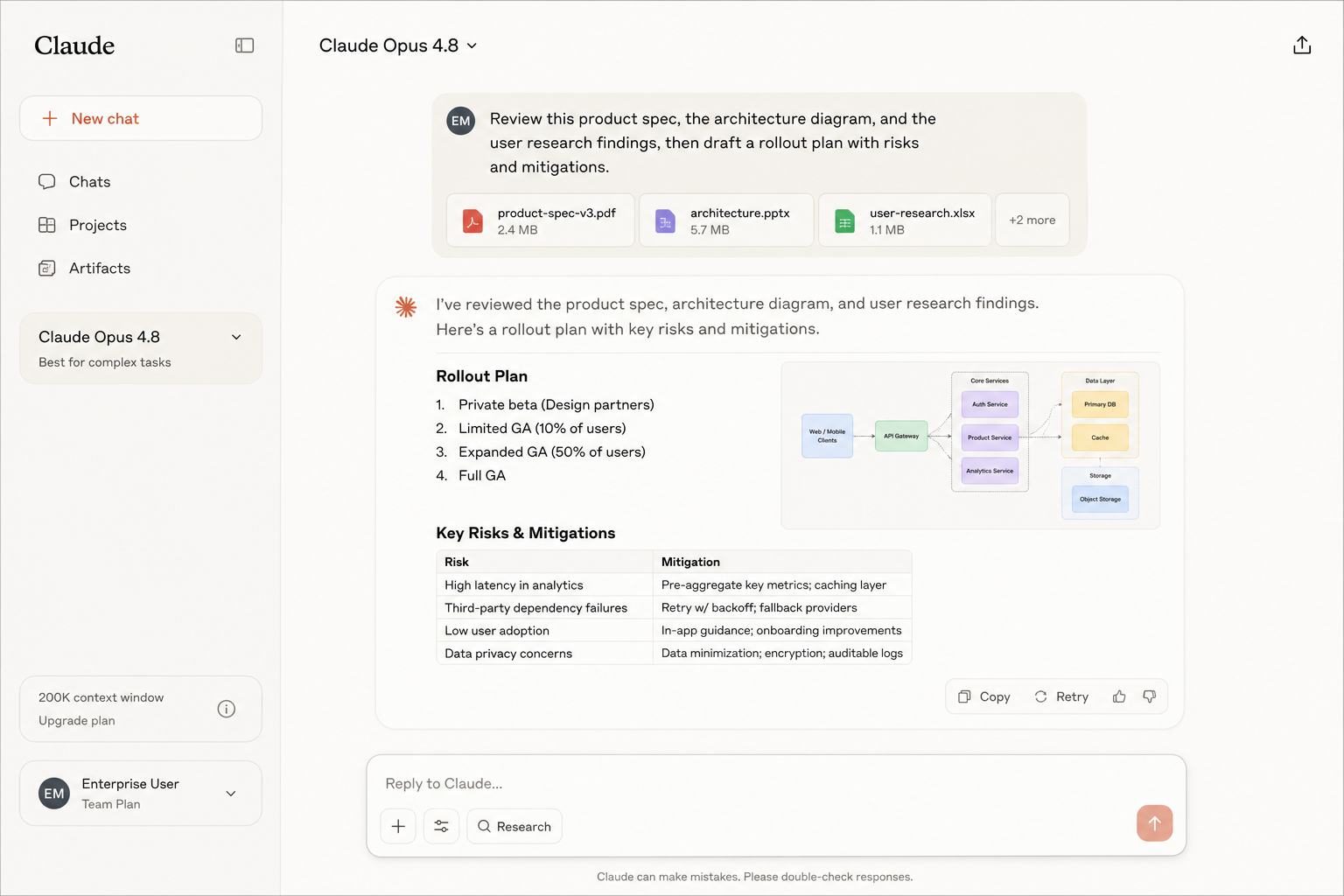
- Highest reliability on extended agent sessions
- Strong at ambiguous spec interpretation
- Improved multimodal document reasoning vs 4.7
Meta
Llama 4 Scout
No other production model comes close to Scout's ten-million-token context window, a scale that eliminates the need for retrieval-augmented generation in most real-world document-heavy workflows. The sparse mixture-of-experts architecture keeps active parameter count at 17B, which is what makes deploying Scout on a single NVIDIA H100 with quantization genuinely achievable rather than aspirational. For legal discovery, longitudinal research analysis, or full-repository code comprehension, loading everything into a single context call is qualitatively different from chunking and retrieving: you get exact references, no missed connections between distant documents, and consistent instruction-following across the entire input.
Accuracy at the far end of the context window degrades far less sharply than earlier long-context models, which have historically been unreliable past 200K tokens. There is no API cost at self-hosted scale, which makes Scout compelling for volume workloads where frontier-model pricing would be prohibitive. The tradeoff is that you need your own serving infrastructure or a hosting provider that supports it — this is not a plug-in-API-key model.
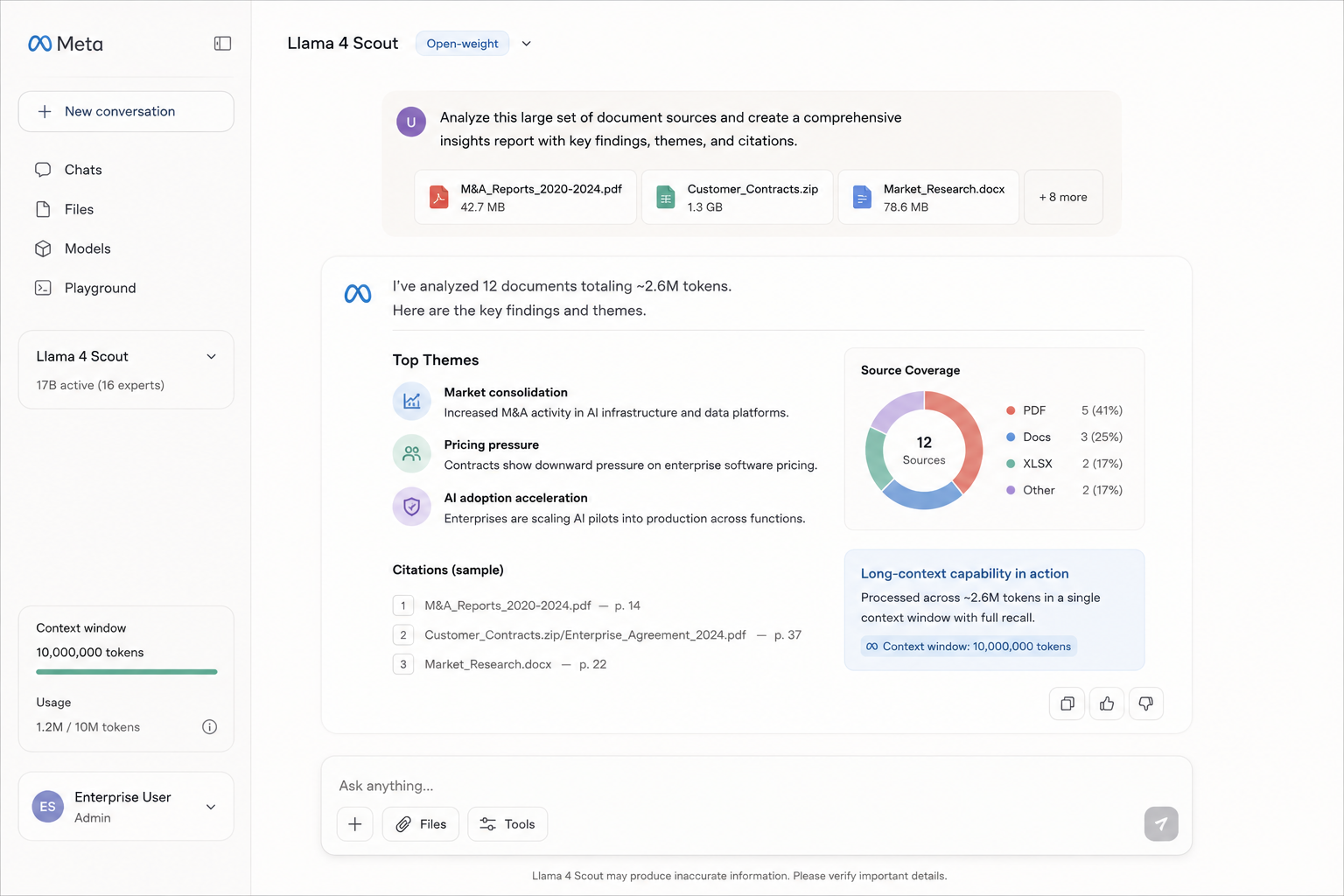
- 10M-token context — the largest of any production model
- Fits on a single H100 with quantization
- Ideal for legal, research, and repository-scale tasks
- No API cost — self-host for volume workloads
DeepSeek
DeepSeek V4 Flash
DeepSeek V4 Flash is the cost outlier of 2026: at $0.14 input and $0.28 output per million tokens, its output pricing is roughly 107× cheaper than GPT-5.5 Pro, which is not a rounding error — it changes the economics of high-volume inference pipelines entirely. The 284B total / 13B active mixture-of-experts architecture is what makes that price point possible: only 13B parameters are active per forward pass, so compute cost scales with active params rather than total model size.
Reasoning and coding benchmark scores are competitive with models several times more expensive, which has driven significant adoption among teams that need frontier-class quality at scale but cannot justify frontier-class pricing. The 1M context window handles long-document workflows without the chunking overhead that smaller-context models require, and tool-calling performance is solid for agentic pipelines. The main caveat for enterprise teams is the Chinese-lab origin and the associated data-sovereignty considerations, DeepSeek V4 Flash is excellent for teams that have assessed and accepted that tradeoff, and a non-starter for those who have not.
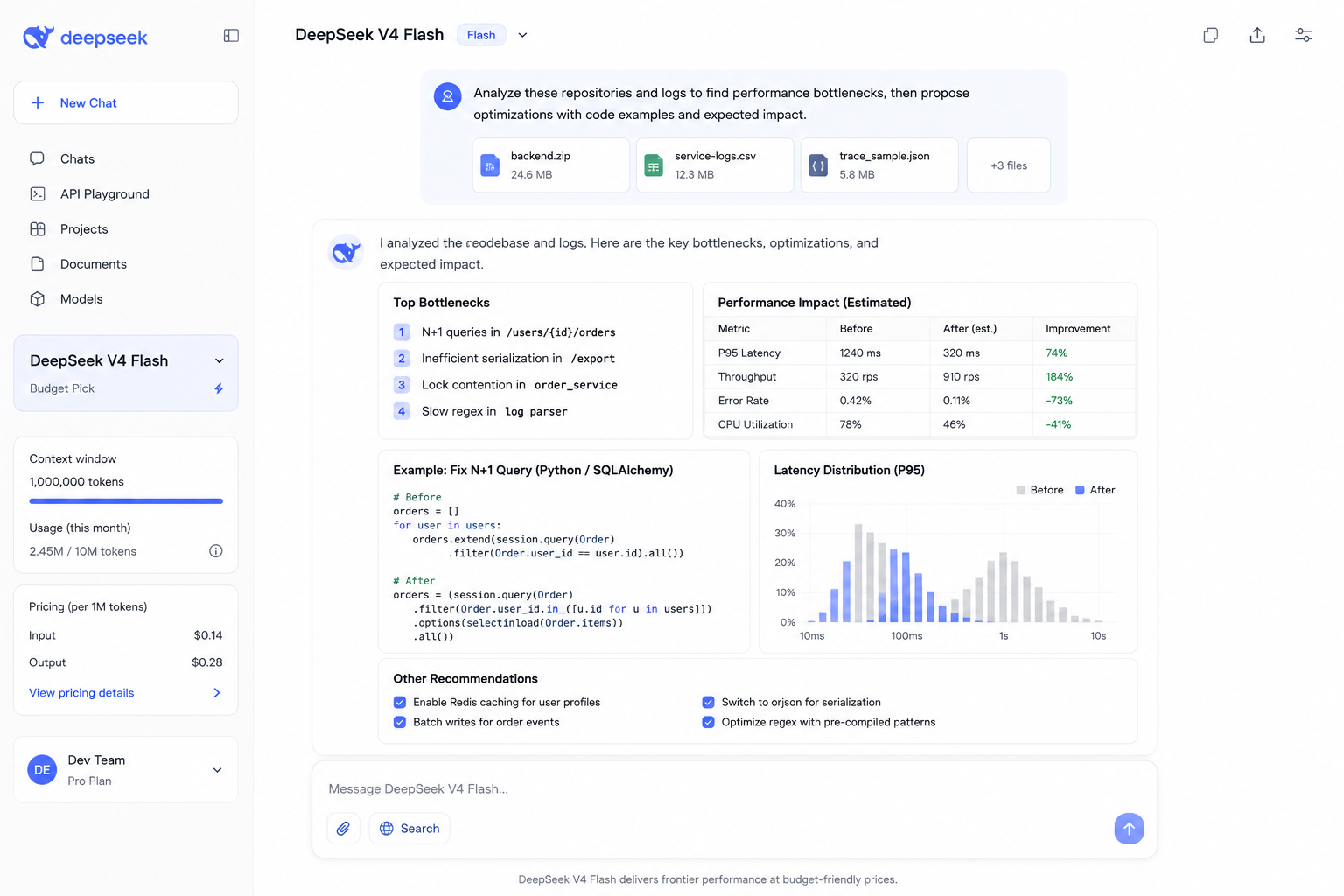
- 107× cheaper output than GPT-5.5 Pro
- MoE architecture: 284B total, 13B active per pass
- Strong for high-volume coding and reasoning at scale
- 1M context window for long-document workflows
Mistral AI
Mistral Large 3
Mistral Large 3 is the most complete open-weight option for teams whose requirements explicitly exclude Chinese-lab models — an Apache 2.0 license, European infrastructure, and commercially redistributable weights make it the cleanest fit for regulated-industry deployments. The 256K context window handles the majority of real-world enterprise document tasks without requiring the specialist serving hardware that 1M+ windows demand, and native multimodal capability covers image understanding and document parsing at quality levels competitive with earlier frontier closed models. EU data-residency is a practical advantage rather than a marketing claim: Mistral operates European infrastructure and the license permits deployment within regional data-sovereignty boundaries without additional agreements.
Instruction-following and coding quality are competitive with the top instruction-tuned closed models in most benchmarks, which means teams are not taking a major capability hit in exchange for the open-weight flexibility and licensing clarity. For European organizations, compliance-sensitive deployments, or teams that simply want full control over their inference stack with no ongoing API dependency, Mistral Large 3 is the default recommendation in the non-Chinese open-weight tier.
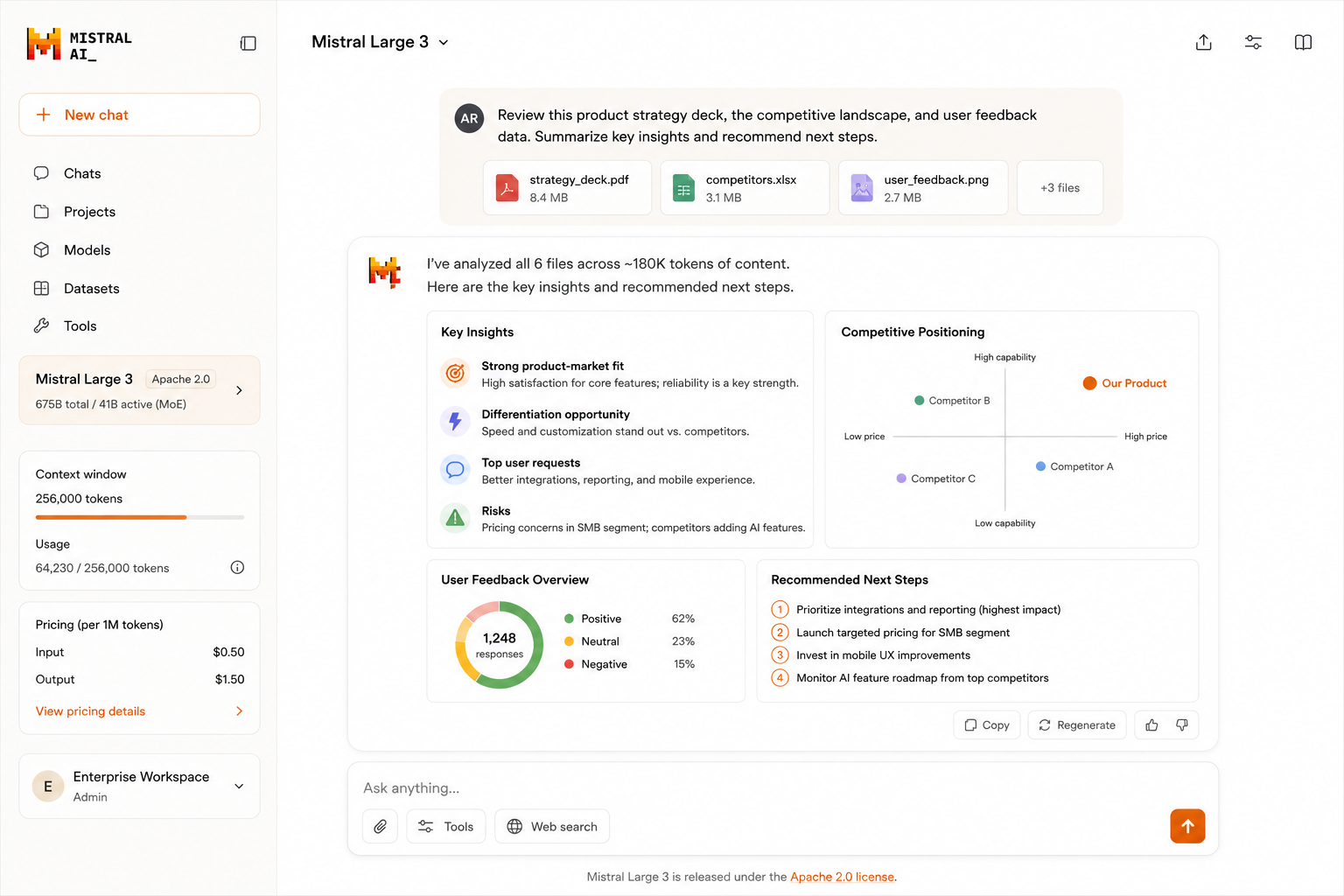
- Apache 2.0 — redistributable, fine-tunable commercially
- 256K context with native multimodal capability
- EU data-residency-friendly self-hosting
- Competitive with top instruction-tuned closed models
Benchmark Comparison Table
Key metrics across the models that matter most for long-context and multimodal workloads. Scores sourced from official documentation and third-party evaluations (June 2026).
Long-Context Leaders
#1 Extreme Context
Llama 4 Scout — 10M tokens
No other production model comes close to Scout's ten-million-token context window — a figure that shifts the ceiling of what a single inference call can actually hold. Ten million tokens is enough to load an entire software repository, a decade of financial filings, or a full legal case including exhibits, all in one go without chunking or retrieval hacks. Meta designed Scout around a sparse mixture-of-experts architecture with 17B active parameters, which is what makes running it on a single NVIDIA H100 with quantization genuinely feasible rather than just technically possible. That single-GPU story is significant because it puts extreme-context processing within reach of teams who are not operating hyperscaler infrastructure.
Scout's retrieval accuracy across the full window is remarkably flat compared to earlier long-context models that degraded sharply past 100K tokens — the model does not effectively "forget" context that was inserted early in the prompt. The tradeoff is that Scout is an open-weight model, so you will need either your own serving setup or an API provider that hosts it, and prompt-engineering discipline matters more at this scale because padding a 10M window with noise is expensive.
For legal discovery, longitudinal research analysis, or large codebase comprehension, Scout is in a category of its own.
#2 Frontier Closed + Long
Gemini 3.5 Flash — 1M tokens + Multimodal
If you want 1M-token context without the overhead of self-hosting, and you also need multimodal reasoning across text, images, video, and audio, Gemini 3.5 Flash is the default recommendation for mid-2026. Google explicitly positions it for agentic execution and long-document understanding, which means the model has been tuned not just to fit long prompts but to reason over them coherently and take multi-step actions on their contents.
At $1.50 input / $9.00 output per million tokens it is significantly cheaper than GPT-5.5 while covering the same context window, which matters a great deal at the scale of production pipelines processing thousands of long documents daily. Gemini 3.5 Flash handles native video frame analysis in a single inference call — no separate speech-to-text or frame-sampling pipeline needed — which is a meaningful architectural simplification for multimedia document workflows. It also supports native audio input, making it one of only a small number of models that can process spoken content directly rather than routing through a separate ASR model. Coherence over the full million-token window has been a weak point for previous long-context models; Flash maintains instruction-following quality across the window noticeably better than its predecessors.
For teams building document intelligence pipelines, multimodal agents, or coding assistants that need to hold large codebases in context, Flash covers the most use cases per dollar of any closed model currently available.
#3 Long-Context for Code
Claude Opus 4.8 — 200K tokens with reliability
200K tokens is smaller than Gemini 3.5 Flash or GPT-5.5 on paper, but for software engineering tasks the question is not how many tokens you can fit — it is what the model actually does with them, and Claude Opus 4.8 has a meaningful edge in reliability at this scale. It maintains coherence across long multi-file code reviews where other models begin to lose track of earlier context, drop constraints from the system prompt, or silently contradict instructions that were introduced dozens of turns ago.
For agentic sessions involving 50 or more tool calls — browsing, writing files, running tests, iterating — Opus 4.8 holds the thread of the original task better than any other model we have evaluated. Instruction-following with deeply nested or conditional specifications buried in a lengthy system prompt is a known weakness for most large models; Anthropic has clearly invested in this capability, and it shows in structured workflows where precision matters. Document reasoning is another strength: PDF extraction, table interpretation, and scanned-form understanding all benefit from the model's careful attention to instruction rather than pattern-matching shortcuts.
For teams where a single context-handling failure in production is costly — compliance pipelines, code-generation agents, structured document workflows — the reliability premium justifies the smaller window. Opus 4.8 is the pick when the cost of getting it slightly wrong outweighs the convenience of getting slightly more into the prompt.
Multimodal Capability Breakdown
Image Understanding
Charts, diagrams, screenshots, OCR, document parsing. Best closed: Gemini 3.5 Flash. Best open-weight: Llama 4 Maverick or Qwen3-VL.
- Top pick: Gemini 3.5 Flash
Document & OCR Reasoning
PDF extraction, table interpretation, scanned form understanding. Claude Opus 4.8 is best for document reasoning with careful instruction-following.
- Top pick: Claude Opus 4.8
Video Understanding
Frame analysis, action recognition, temporal reasoning. Google Veo 3 and Gemini 3.5 Flash lead here. The native multi-modal approach beats a separate STT or frame pipeline.
- Top pick: Gemini 3.5 Flash
Audio & Speech
Native audio arrived with GPT-5.5 in April 2026 — speech as direct input, no STT step needed. For voice agents, GPT-5.5 and Gemini 3.5 Flash both support it natively.
- Top pick: GPT-5.5
Chart & Structured Data
Interpreting complex charts, spreadsheets, and structured visual data. GPT-5.5 and Claude Opus 4.8 are both strong. For image generation with charts, Recraft V4 leads.
- Top pick: GPT-5.5 / Claude Opus 4.8
Screen & UI Understanding
Parsing UI screenshots, automating web interfaces, visual QA. GPT-5.5 leads on UI understanding. Qwen3-VL is the open-weight alternative for custom browser agents.
- Top pick: GPT-5.5
Open-Weight Models Worth Knowing
Llama 4 Scout
Meta's extreme long-context specialist. 10M tokens, 17B active params, deployable on a single H100. The only production model at this context scale, built for legal discovery, longitudinal research, and full-codebase comprehension where no chunking or retrieval layer should be necessary. Its sparse MoE architecture keeps inference cost manageable even at this scale, and accuracy degrades far less than expected across the full window length.
Needs your own serving infrastructure or a compatible API host, but the flexibility that comes with open weights is a real advantage for teams with data-residency or customization requirements. No commercial license restrictions for most use cases.
Llama 4 Maverick
The balanced Llama 4 option for teams that need multimodal enterprise capability without the extreme-context requirement of Scout. 1M context, 17B active params across 128 experts — a mixture-of-experts design that keeps inference affordable while handling image and text inputs natively in a single call. Maverick performs well on multilingual tasks, which makes it a realistic option for international deployments where a closed-model API introduces latency or compliance friction.
The model is strong on visual question answering and document understanding, putting it in direct competition with Gemini 3.5 Flash for open-weight use cases. Self-hosting requires meaningful GPU investment at 1M context, but the model's efficient active-parameter count makes batch inference viable. A solid default recommendation for enterprise teams that want open-weight multimodal without compromising on context length.
Mistral Large 36
75B total / 41B active parameters in a mixture-of-experts architecture, with 256K context and multimodal input support. The strongest open-weight option from a non-Chinese lab, which matters for teams with supply-chain or data-sovereignty constraints that rule out Meta and Chinese-origin models. EU data-residency is a practical advantage — Mistral is a French company with European infrastructure and a redistributable license that allows deployment in regulated environments without negotiating enterprise agreements.
Multimodal support covers image understanding and document parsing at a quality level that is competitive with earlier frontier models. The 256K context is sufficient for most enterprise document workflows without requiring the specialist serving hardware that 1M+ windows demand. For European organizations that need a capable, deployable, legally uncomplicated open-weight model, Mistral Large 36 is the most credible option available.
GLM-5
Z.ai's latest GLM release carries an MIT license, the most permissive in this category, which makes it the best open-source choice for teams that need to modify, redistribute, or productize the model without restriction. Coding and agentic capabilities are competitive with models several times its size, and cost per token at inference is low enough that it becomes viable for high-volume pipelines where frontier closed models would be prohibitively expensive.
Tool-calling support is solid, and the model handles multi-step agentic tasks reliably enough for production workflows with appropriate guardrails. Teams that are comfortable working with a Chinese-lab model will find GLM-5 the most capable MIT-licensed option currently available, substantially ahead of earlier open-weight alternatives in its compute class.
Context length is competitive for most enterprise document tasks. The MIT license also means no friction around fine-tuning on proprietary data, which opens up adaptation workflows that are restricted or expensive with other models.
Qwen3-Coder-480B
Alibaba's 480B total / 35B active parameter MoE model is purpose-built for agentic coding, browser use, and tool-calling workflows — and it is the most capable open-weight model in this niche. 256K context handles most realistic codebase sizes comfortably, and the model's tool-calling accuracy is notably high for a model that can be self-hosted, which matters for teams building agents that need to call external APIs reliably without frequent parsing failures.
Browser-use benchmarks place it ahead of every other open-weight model and within range of closed frontier models, making it a serious option for web automation and UI testing agents. The 35B active parameters keep per-token inference cost reasonable even at scale, and the sparse architecture means the model can run on hardware that a 480B dense model would make completely impractical. For teams building code agents, CI automation, or developer tooling on top of a self-hosted foundation, Qwen3-Coder-480B is the current benchmark to beat in the open-weight tier.
Mistral Medium 3.5
A 128B dense model with 256K context and frontier-class multimodal support, self-hostable on four GPUs, which makes it the most capable model in this list that teams with serious but not extreme GPU budgets can actually run themselves. Unlike the MoE models elsewhere in this section, Medium 3.5's dense architecture gives it more predictable latency characteristics, which is valuable for latency-sensitive applications where MoE routing variance is a problem.
Multimodal support covers image understanding, document parsing, and coding with quality that has closed most of the gap with frontier closed models. The four-GPU requirement (four H100s or equivalent) is achievable for well-resourced teams and significantly cheaper than building out the infrastructure needed for Scout or Maverick at scale.
For teams that want coding, reasoning, and multimodal capability in a single model with full deployment control and no per-token API costs, Medium 3.5 offers the best value proposition in the open-weight ecosystem. Its redistributable license and European origin also make it the easiest fit for regulated-industry deployments.
Pricing Tiers for 2026
Which Model for Which Job?
No single model wins every workload. Use this matrix to match the task to the right tool before you write a single line of production code.
How to Actually Pick a Model for Production
The leaderboard is the wrong artifact. Here's a three-step process that produces decisions you can trust.
Run a domain reproduction, not a benchmark lookup
Take 100–500 of your actual production prompts and run them through your top three candidate models with your own harness. Score with an LLM-as-judge or your own evaluators. The gap between vendor benchmark scores and your reproduction is the only signal that matters. A 35-point spread between SWE-bench Verified and SWE-bench Pro — as seen with some March 2026 models — is a real warning sign that doesn't show up in the headline number.
Measure reliability decay, not just peak accuracy
Most public benchmarks measure performance on a single, isolated task. Production agents don't work that way. Track what happens to success rate as session length grows — most frontier models lose 15–40% of headline accuracy at 50+ tool-call sessions. If your workload involves long-running agents, test explicitly for reliability at depth, not just in isolation. Claude Opus 4.8 is unusually strong here; Gemini 3.5 Flash is faster but decays earlier on complex tasks.
Cost-adjust your scores against your actual volume
Headline benchmark scores hide 5–10× cost differences. A model scoring 5% higher on GPQA Diamond might cost 3× more per million tokens. Calculate expected monthly spend at your projected volume for each candidate. With 2026's pricing (DeepSeek V4 Flash at $0.14/M input vs. GPT-5.5 at $5.00/M), the cost-adjusted leaderboard reorders dramatically. For many workloads, a cheaper model at higher call volume beats a smarter model used sparingly.
Access every model listed here through one API
AI/ML API is a unified, fast, and affordable gateway to every frontier model — GPT-5.5, Claude Opus 4.8, Gemini 3.5 Flash, Llama 4 Scout, Grok 4.3, DeepSeek V4 Flash, GLM-5.2, and more. One key. One endpoint. No infra to manage. Swap models in a single line of code to run your domain reproduction and find your optimal cost-quality point.
Frequently Asked Questions
What is the best LLM for long-context tasks in 2026?
It depends on what "long-context" means for your workload. Llama 4 Scout offers the largest context window at 10 million tokens and is the answer for truly massive document sets — entire repositories, legal case files, or multi-year research archives. For a fully managed API experience with 1M tokens and strong reasoning, Gemini 3.5 Flash and GPT-5.5 are the top choices. If context stays under 200K but reliability matters more than window size, Claude Opus 4.8 is the most consistent option for complex multi-step work.
Which model is best for multimodal applications?
Gemini 3.5 Flash is the default recommendation for multimodal pipelines — it handles text, images, documents, audio, and video natively, with a 1M-token context window at the lowest price point among US frontier labs ($1.50 input / $9.00 output per million tokens). GPT-5.5 is the stronger choice if native audio input is critical, since it launched with speech-as-input support in April 2026. For open-weight multimodal work, Llama 4 Maverick and Mistral Large 3 are both genuinely capable.
What is GLM-5.2 and how does it compare to other models?
GLM-5.2 is the latest model in Zhipu AI's (Z.ai) GLM series. It's released under the MIT license, making it freely usable and modifiable for commercial purposes. It's competitive on coding and agentic tasks at very low self-hosted inference cost, with strong multilingual coverage including Chinese. It's not a direct replacement for frontier closed models on complex reasoning — but for high-volume production workloads, domain-specific fine-tuning, and teams that want full open-source flexibility, it's one of the stronger options available today.
Is Claude Opus 4.8 better than Opus 4.7?
Claude Opus 4.8 builds directly on Opus 4.7 with improvements to agentic reliability, multimodal document reasoning, and extended session coherence. Opus 4.7 itself was a significant jump over 4.6 — a roughly 7-point improvement on SWE-bench Verified when it launched in April 2026. For new production workloads, Opus 4.8 is the current recommendation. If you're running Opus 4.7 in production, the upgrade path is straightforward through AI/ML API since pricing remains flat.
How much cheaper are LLMs in 2026 compared to 2025?
The year-over-year price drop across frontier models is roughly 40–80%. As a reference point: output tokens that cost around $30 per million from a leading US lab in early 2025 can now be served by capable alternatives like DeepSeek V4 Flash at $0.28 per million — over 100× cheaper. Even among US lab closed models, Grok 4.3 at $2.50 output and Gemini 3.5 Flash at $9.00 output represent substantial compression versus 2025 pricing. The economics of building AI-powered products changed significantly in 2026.



