
Claude Opus 4.8: Sharper judgment, better agentic reliability
What is Claude Opus 4.8?
Claude Opus 4.8 is the latest entry in Anthropic's Opus model family, released on May 28, 2026. It builds incrementally on Opus 4.7, tightening performance across coding, agentic tasks, reasoning, and knowledge work rather than chasing headline benchmark numbers at the expense of real-world reliability.
The core bet Anthropic is making with this release is straightforward: for teams that run autonomous agents, write and review complex code, or depend on Claude to surface its own blind spots, Opus 4.8 is a meaningfully more trustworthy collaborator. The pricing stayed exactly the same. The capabilities grew.
Anthropic describes this as a "modest but tangible improvement" on 4.7, which is honest positioning. It's not a ground-up architectural overhaul. What it is: a smarter, more self-aware agent that costs exactly what the last version did and runs 2.5× faster in fast mode at one-third the fast-mode price.
What's new in Claude Opus 4.8?
This release bundles model improvements with three substantial platform additions. The model and the features were designed together — each feature leans on something Opus 4.8 does better than its predecessor.

The model improvements
Better agentic judgment
Opus 4.8 asks the right questions before making big changes, catches its own mistakes mid-task, and pushes back on plans that don't hold up. Early testers at Cursor report meaningfully more efficient tool calling — fewer steps to reach the same result.
Improved honesty & uncertainty handling
A long-standing weakness in AI agents is overconfidence, claiming progress when the evidence is thin. Opus 4.8 is four times less likely than 4.7 to let a coding flaw pass without flagging it. Investment analysts at Visible Alpha noted this concretely: it proactively flagged input and output issues that other models quietly ignored.
Stronger legal & knowledge work
On the Legal Agent Benchmark, Opus 4.8 is the first model to break 10% on the all-pass standard. For teams running high-stakes professional workflows — legal, compliance, financial — that's not a marginal difference in a leaderboard; it's the point at which you can start handing off real attorney work with confidence.
Best-in-class computer use
On Online-Mind2Web, a benchmark for browser agents navigating live web tasks, Opus 4.8 scores 84%, a jump over both Opus 4.7 and GPT-5.5. It's the only model to complete every case end-to-end on Magi's Super-Agent benchmark, beating prior Opus versions and GPT-5.5 at cost parity.
Stronger alignment baseline
Anthropic's alignment team found Opus 4.8 reaches new highs on prosocial traits, supporting user autonomy, acting in users' interests — and has substantially lower rates of misaligned behavior like deception or cooperation with misuse than its predecessor.
Cleaner long-session collaboration
Testers who work with the model across extended writing and analysis sessions report it carries voice, style context, and technical direction better across turns. Less re-explaining, better signal-to-noise on outputs.
The three new platform features
Dynamic Workflows in Claude Code
Now in research preview for Enterprise, Team, and Max plan users, this feature lets Claude plan a large job, spin up hundreds of parallel subagents to execute it, and verify the results before reporting back. The stated example from Anthropic: codebase-scale migrations across hundreds of thousands of lines of code, from kickoff to merge, using your existing test suite as the quality bar. That's not a PR summary, it's autonomous refactoring at a scale that previously required a team.
Effort Control on claude.ai and Cowork
A new slider next to the model selector lets users choose how hard Claude works on a given response. Three effective levels:
Mid-task system prompt updates via the Messages API
Developers can now inject system entries directly inside the messages array without breaking the prompt cache or routing instructions through a user turn. In practice, this means you can update Claude's permissions, token budget, or environment context on the fly as an agent runs. A small change in the API spec that makes a real difference in how cleanly you can build stateful agentic systems.
Benchmarks and real-world performance
Anthropic's benchmarks for Opus 4.8 span four domains: coding, agentic skills, reasoning, and practical knowledge work. The biggest verified gains are in agentic coding and computer use, which maps directly to the use cases where the Opus line is most commonly deployed.
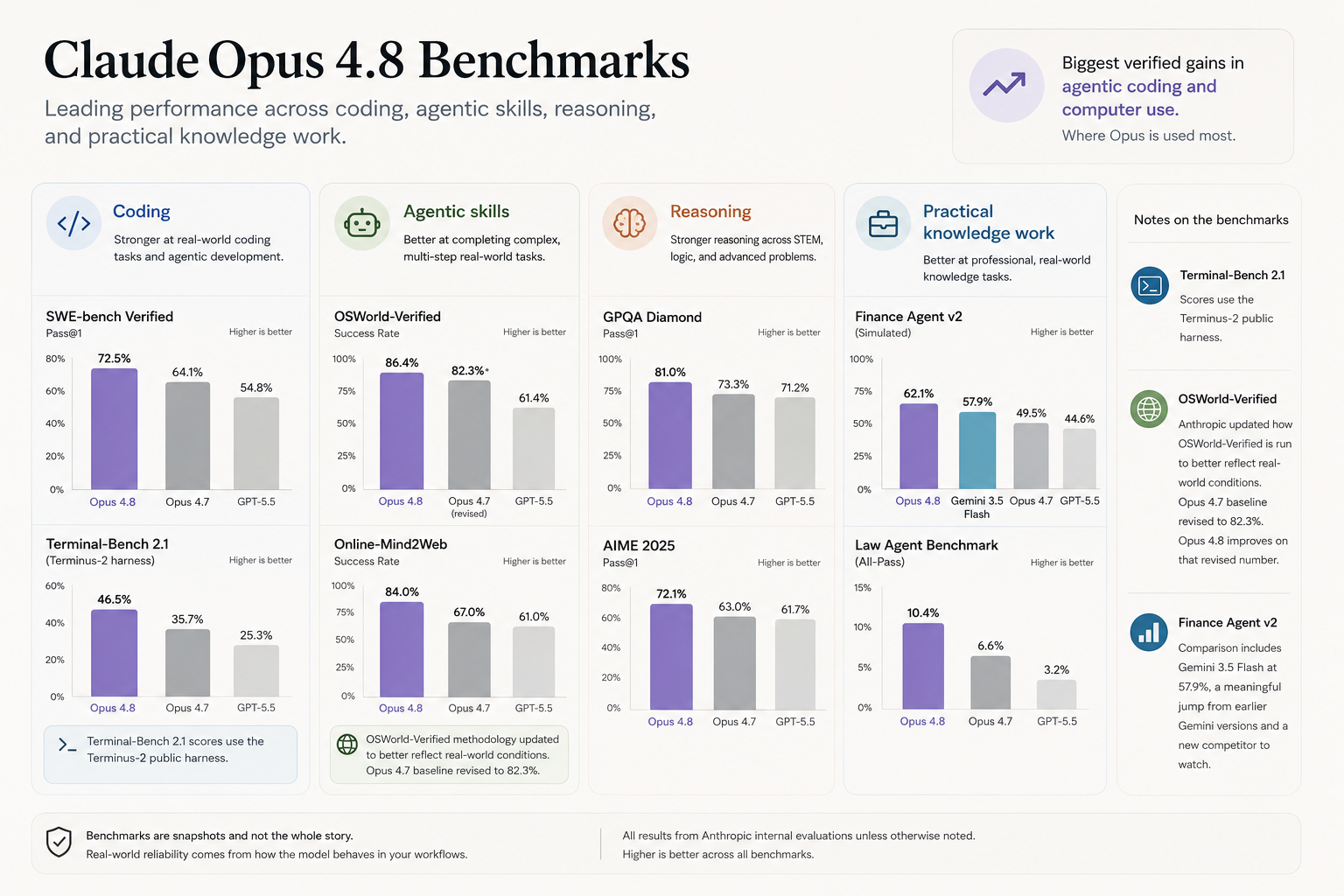
A few things worth calling out in the benchmark picture. First, the Terminal-Bench 2.1 scores use the Terminus-2 public harness. Second, Anthropic updated how they run OSWorld-Verified to better reflect real-world conditions, revising the Opus 4.7 baseline to 82.3%, Opus 4.8 improves on that revised number. Third, the Finance Agent v2 comparison includes a newly competitive Gemini 3.5 Flash at 57.9%, which is a meaningful jump from earlier Gemini versions and sets up a competitive landscape worth watching.
What is Claude Opus 4.8 actually good for?
The honest answer is: it's good for the same things Opus was always good for, but with fewer edge cases that require you to double-check the model's work. That might sound like faint praise. In production, it's the difference between an AI tool and a reliable AI collaborator.
Autonomous coding and code review
Opus 4.8's primary upgrade in coding isn't raw generation speed, it's the reduction in silent failures. It's four times less likely to produce flawed code without remarking on the flaw. For teams that trust their CI/CD to catch errors, that statistic is mostly noise. For teams running long agentic coding sessions where Claude is committing changes autonomously, it's genuinely important. Pair it with Dynamic Workflows and you can run codebase migrations or refactors at a scale that simply wasn't feasible with earlier models.
Research and document synthesis
For tasks like literature review, competitive analysis, or financial document workflows, Opus 4.8 produces denser, more information-rich outputs with better signal-to-noise. Visible Alpha's investment team described it as noticeably better at flagging when its inputs or outputs are suspect — something other models leave to the user to catch.
Legal and compliance-adjacent work
Both EvenUp and CoCounsel's Thomson Reuters team independently reported meaningful improvements in consistency and reasoning quality for high-stakes professional workflows. The Legal Agent Benchmark result (first to clear 10% on all-pass) is a useful concrete signal: these aren't soft claims about "reasoning ability" but performance on tasks that require coordinated multi-step legal analysis with real correctness requirements.
Multi-step agent tasks
Any workflow that runs Claude autonomously for more than a few turns benefits from the improved judgment in 4.8. It asks better questions before making irreversible changes, it's more likely to flag when it's uncertain, and it's less likely to get confidently lost in the middle of a long task. Companies like Devin's Cognition report that it uses tools more cleanly and follows instructions with the consistency their autonomous engineering workloads need to run unattended.
Long-form writing and editorial work
Testers like Katie Parrott (Staff Writer at Quora) highlight the model's ability to carry voice and style direction across long sessions. For writers, editors, and content teams working on extended documents, that translates to less re-prompting and more coherent output over time.
Browser-based automation
With an 84% score on Online-Mind2Web and the best computer-use and browser-agent performance in current testing, Opus 4.8 is the most capable choice for tasks that involve navigating real web interfaces — filling forms, extracting structured data from live pages, or running end-to-end flows across web tools.
Claude Opus 4.8 vs other models: is it worth the upgrade?
The honest model comparison looks like this:
The bottom line on the upgrade question: if you're currently running Opus 4.7 in production, moving to 4.8 is a no-brainer. Same pricing, the same model string structure, better performance on the tasks that matter most in agentic deployments. The only reason to delay is if your deployment pipeline requires extensive re-testing, but for most teams, the model string swap is the only change required.
Claude Opus 4.8 pricing and availability
Anthropic kept pricing identical to Opus 4.7 — a deliberate decision that they've made consistently across the 4.x Opus line. Fast mode pricing dropped significantly, which changes the economics for time-sensitive applications.
What comes after Opus 4.8?
Anthropic was unusually specific about their roadmap in the 4.8 announcement. Two things are explicitly coming:
First, models that offer "many of the same capabilities as Opus at a lower cost", which is the standard Sonnet / Haiku progression, but signals that the next Sonnet tier will close the capability gap to Opus in meaningful ways.
Second, and more interesting: a new model class with "even higher intelligence than Opus." This is Claude Mythos, currently available in preview to a small number of organizations through Project Glasswing for cybersecurity research. Anthropic notes they're making "swift progress" on developing the cyber safeguards Mythos-class models require before general release, and expect to bring them to all customers "in the coming weeks."
For developers: the current rational choice is Opus 4.8 for serious agentic and knowledge-work applications, with Sonnet for high-volume use cases where cost per call matters. Mythos is worth watching, if it's even a significant step above Opus, it would reshape what's possible in autonomous workflows.
Ready to build with Claude Opus 4.8?
Access Anthropic models through AI/ML API and integrate the latest Claude into your product in minutes.
Frequently asked questions
What is the Claude Opus 4.8 model string for the API?
The official model identifier is claude-opus-4-8. Pass this as the model parameter in any Anthropic API call. It works identically to previous Opus model strings — if you're migrating from Opus 4.7 (claude-opus-4-7), swapping the string is the only change required in most integrations.
Is Claude Opus 4.8 more expensive than Opus 4.7?
No. Standard pricing is unchanged at $5 per million input tokens and $25 per million output tokens — the same as Opus 4.7. Fast mode pricing actually dropped: it now costs $10 input / $50 output per million tokens, which is three times cheaper than fast mode was for previous Opus models, while running at 2.5× the standard speed.
What does Effort Control actually do, and which plans get it?
Effort Control is a new setting in claude.ai and Cowork that sits next to the model selector. It lets you choose how much thinking and token usage Claude applies to a given response. Higher effort produces better results; lower effort responds faster and uses rate limit more slowly. There are three levels: High (default — best quality/speed balance), Extra (recommended for difficult or complex tasks, available as xhigh in Claude Code), and Max (maximum token spend for critical deliverables). Effort Control is available on all plans — Free, Pro, Team, and Enterprise.
How does Opus 4.8 compare to Opus 4.7 on coding tasks specifically?
The headline improvement is a four-fold reduction in silent coding errors — Opus 4.8 is four times less likely than 4.7 to produce flawed code without flagging the flaw itself. On CursorBench (Cursor's internal evaluation), 4.8 outperforms all prior Opus versions at every effort level, with meaningfully more efficient tool calling — fewer steps to reach the same outcome. On Terminal-Bench 2.1, 4.8 scores higher than 4.7 using the Terminus-2 public harness. It also fixed comment-verbosity and tool-calling issues that teams like Cognition reported with Opus 4.7.
When will Claude Mythos be available to all users?
Anthropic hasn't announced a firm date. As of the Opus 4.8 release (May 28, 2026), Claude Mythos Preview is available only to a small number of organizations through Project Glasswing, currently focused on cybersecurity research use cases. Anthropic says they expect to bring Mythos-class models to all customers "in the coming weeks" once the required cyber safeguards are finalized. Given they used the phrase "swift progress," a general release sometime in June or July 2026 is plausible — but unconfirmed.



