
Gemini 3.2: What to Expect and What’s New
Release overview: goals and positioning
What Gemini 3.2 is, who it's for, and why Google is moving faster than before.
Release focus
Gemini 3.2 is shaping up to be Google's most aggressively priced Flash-tier model yet. Based on what's surfaced in AI Studio internal metadata and the Gemini iOS app, the model isn't a ground-up rebuild, it's a targeted quality-and-cost update inside the Gemini 3 series. The clearest signals point to better coding output (especially animated HTML and 3D generation), faster inference than its predecessor, and a price cut that halves the input cost compared to Gemini 3 Flash.
This cadence matters as much as the model itself. Gemini 3 Flash arrived in December 2025, Gemini 3.1 Flash-Lite followed in early 2026, and now 3.2 is appearing less than three months after 3.1. Google is clearly shifting to a software-style release rhythm: smaller, more frequent updates rather than big-bang launches. For teams running production systems on Gemini, that means faster improvements but also a need for tighter version-pinning hygiene.
- Status as of May 15, 2026: Gemini 3.2 Flash has not been officially announced. Everything in this guide is based on credible pre-release signals — leaked app strings, LM Arena benchmark appearances, and AI Studio metadata. Treat numbers as directional until Google publishes official release notes.
Target audiences and tiers
Core model updates
What's actually changing under the hood and what that means in practice.
Architecture and inference improvements
Gemini 3.2 Flash is almost certainly not a new architecture from scratch. Based on the pattern Google has used across the 3.x series — and the LM Arena benchmark behavior observed before the model was identified, this is most likely an efficiency-focused tuning pass on the Gemini 3 Flash base, optimizing for throughput and cost-per-output without sacrificing reasoning depth on standard tasks. Where Gemini 3.1 Pro took five and a half minutes on animated HTML generation, the new model did it in under two — a 2.7× speedup on the same prompt.
If those signals hold up, developers can realistically expect lower time-to-first-token and higher throughput on burst workloads, exactly what high-frequency production systems need from a Flash model.

Accuracy and reasoning upgrades
The Gemini 3 series already set a high bar. Gemini 3 Flash scored 78% on SWE-bench Verified (better than both Gemini 3 Pro and the entire 2.5 series) and hit 90.4% on GPQA Diamond. Gemini 3.2 is expected to narrow the gap between Flash and Pro performance further, particularly in coding and structured reasoning tasks.
The knowledge cutoff shifting to January 2026 (from Gemini 3's January 2025 cutoff) is a practical win for teams doing retrieval-augmented generation. More recent training data means fewer gaps to plug with Search Grounding, and tighter base accuracy on recent events before you even add retrieval.
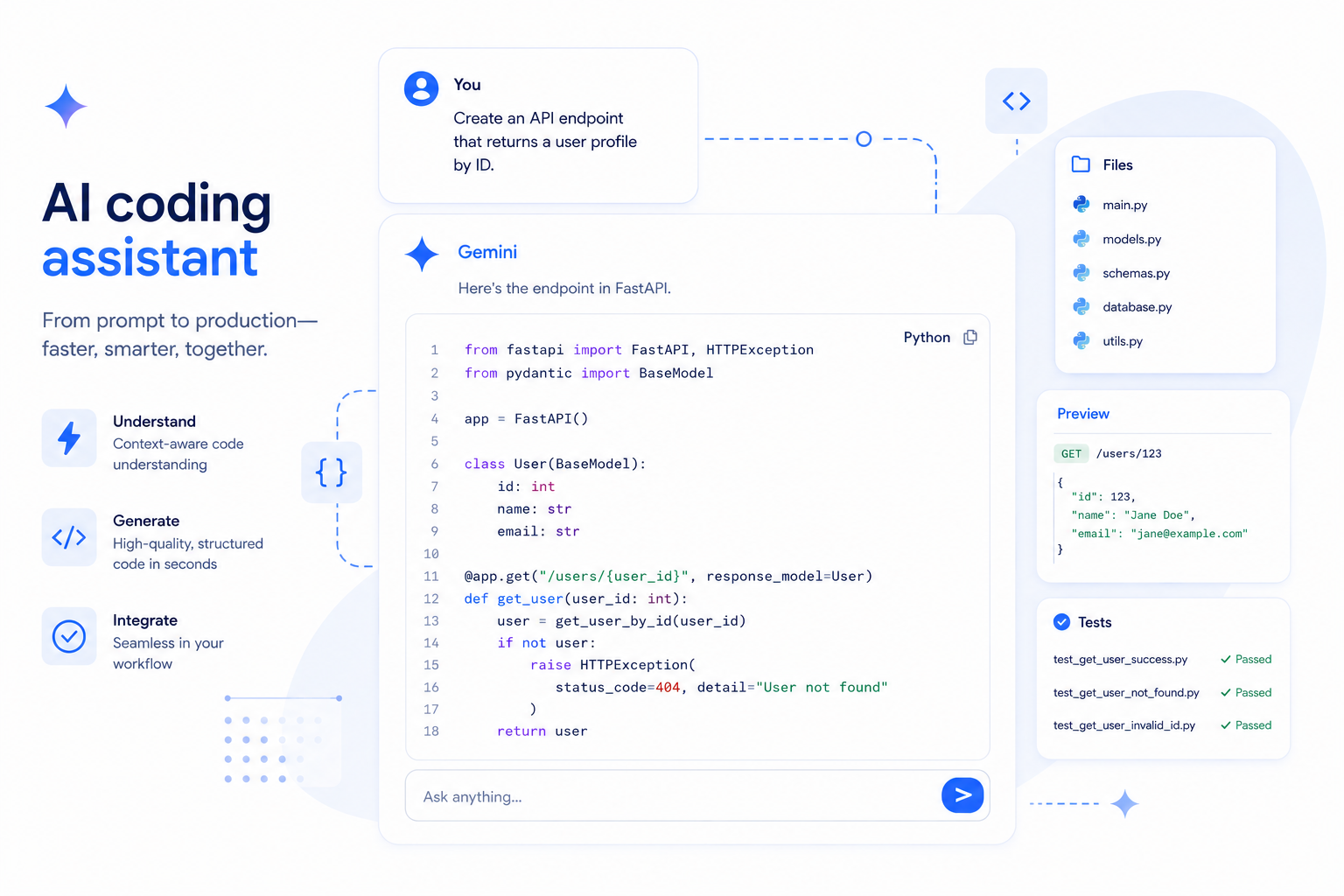
Multimodal capabilities
Early anonymous Arena outputs associated with 3.2 showed upgraded 3D generation and animation, generating functional, interactive HTML canvas and WebGL scenes from natural language prompts. This lines up with leaked descriptions mentioning "3D generation and animation capabilities nearing Gemini 3.1 Pro quality at Flash speeds." Image and audio understanding are expected to remain at parity with Gemini 3 Flash, while the model's ability to turn visual reasoning into working code appears to have improved meaningfully.
Developer & API changes
New endpoints and SDK updates
The model string will almost certainly be gemini-3.2-flash or a dated preview variant like gemini-3.2-flash-preview. Based on how Google has handled 3.x rollouts, expect the model to land simultaneously in the Gemini API (Google AI Studio), Vertex AI, and Gemini CLI. The OpenAI compatibility layer should map reasoning_effort to Gemini's thinking_level automatically, consistent with existing Gemini 3 behavior.
One more place you can try Gemini 3.2
Alongside Google AI Studio, Vertex AI, and the Gemini CLI, AI/ML API is another option for accessing the model, particularly if you're already using an OpenAI-compatible workflow and want to keep your existing SDK setup.
Pricing implications
Leaked pricing puts Gemini 3.2 Flash significantly below its predecessors:
Breaking changes, deprecations, and migration tips
No confirmed breaking changes yet. But based on the Gemini 3 series pattern, teams should double-check the following before cutting over:
- If you're using
thinking_budgetanywhere, migrate tothinking_level— it's the Gemini 3 standard and likely to be the only supported parameter going forward. - Avoid pairing both parameters in a single request; the developer guide explicitly warns this causes unpredictable behavior.
- Image segmentation (pixel-level masks) is not supported in Gemini 3 Flash or Pro — if you rely on that, stay on Gemini 2.5 Flash with thinking off until an alternative ships.
- Temperature defaults changed in Gemini 3 to 1.0. If you're hardcoding low temperature values for determinism, test thoroughly — you may get looping or degraded output on complex tasks.
Prompting, system instructions, and controls
Changes to instruction-following and temperature controls
The entire Gemini 3 series was designed around the assumption that you'll rely on the model's built-in reasoning rather than manual chain-of-thought scaffolding. That philosophy carries into 3.2: if you were previously wrapping prompts with "think step by step" or "reason carefully before answering," you can strip that out and set thinking_level: "high" instead. The model handles the internal deliberation; your prompts should just tell it what you actually want.
One practical shift: Gemini 3 models are designed to be concise and "guess when information is missing." That's useful in chat-style applications but can surprise teams that expect the model to ask for clarification before acting. If your system prompt requires strict adherence to inputs, be explicit about it — the model won't halt and wait unless you tell it to.
New tools for prompt engineers
The Gemini 3 developer guide recommends several patterns that carry into 3.2: precise, concise input prompts over elaborate few-shot chains; using thinking_level as your main knob for cost-vs-quality trade-offs; and testing media_resolution_high for anything involving dense document parsing. The Batch API is supported across the Gemini 3 series, so long-running content workflows can be moved off synchronous calls to reduce cost and improve resilience.
Product & workspace integrations
Docs, Sheets, and Workspace integrations
Google's Workspace Intelligence strategy means Flash-tier model updates typically reach Workspace features with a short lag behind API availability. Gemini in Docs, Sheets, Gmail smart compose, and the Gemini sidebar across Workspace apps will likely upgrade to 3.2 Flash automatically once the rollout completes, you won't need to opt in, but you also won't have granular version control over which model powers which Workspace feature unless you're on an Enterprise plan with API-level configuration.
Desktop, mobile, and cloud UI
The leaked iOS app screenshots showed a redesigned "Liquid Glass" interface alongside the Gemini 3.2 Flash model string — a pill-shaped prompt box, a pulsating gradient background, and the model picker moved to a top-left dropdown. A new "Agents (Beta)" tab was also visible in the Gemini sidebar, currently a placeholder. Whether this UI ships alongside the model or follows separately is unclear, but the two appear to be staged for the same I/O announcement window.
Regional rollout: based on Google's recent pattern, the EU and EEA can expect a 2–4 week lag behind the US launch while GDPR and EU AI Act compliance reviews complete.
Practical prompt recipes
Copy-paste starting points, ready to test against Gemini 3.2 Flash on day one.
Coding assistant Python · General
You are a concise coding assistant. Given the problem,
return working Python codeand a 2-line explanation. Do not add anything beyond the code and explanation.
If the required inputs are missing, return: "Error: input required.
"Problem: [insert your problem here]Multimodal Q&A Image · Analysis
You are a multimodal analyst. Given an image and a question,
answer in 3–5 bulletsand cite the specific region of the image that supports each point.
If the image is unclear or the question cannot be answered from the image alone,
say so explicitly — do not guess.
Image: [attach]
Question: [insert]RAG synthesis Retrieval-Augmented Generation
You are a research assistant. I will provide context passages followed by a question.
Answer using ONLY the provided context. If the answer is not present in the context,
say "Not found in provided sources." Do not use your background knowledge.
Context:{retrieved_passages}
Question: {user_question}
Format: 2–3 sentences. Cite the passage index in square brackets.Long-form content draft Content Teams
You are an experienced writer. Write a [word count]-word article on the topic below.
Use clear H2 and H3 headings. Write in active voice. Avoid filler phrases and AI-sounding transitions.
Each section must contain at least one concrete example ordata point. End with a practical takeaway paragraph.
Topic: [insert]
Target audience: [insert]
Primary keyword to include naturally: [insert]Animated UI generation 3D · HTML Canvas · New in 3.2
You are a creative front-end developer. Generate a single self-contained HTML file
with embedded CSS and JavaScript that produces the following interactive animation.
The code must run without external dependencies.
Include brief inline commentsexplaining the key animation logic.
Animation description: [describe what you want to see]
Target interaction: [click / hover / scroll / auto-play]Run these prompts against Gemini, GPT, and Claude — same code, three responses. Each recipe above runs identically through AI/ML API. Compare outputs in your terminal in under five minutes.
Quick FAQ
Short answers to the questions most likely landing in your Slack right now.
Is Gemini 3.2 officially released?
Not yet. As of May 14, 2026, it has appeared in the Gemini iOS app, AI Studio metadata, and anonymous LM Arena benchmarks, but there's been no official Google announcement. Google I/O (May 19–20) is the expected launch window.
What's the difference between Gemini 3.2 Flash and Gemini 3.1 Pro?
3.2 Flash is a Flash-tier model — optimized for speed and cost. 3.1 Pro is the current highest-quality non-Ultra model. Early benchmarks suggest 3.2 Flash approaches 3.1 Pro quality on coding tasks specifically, at a fraction of the price. For reasoning-heavy or multi-step work, 3.1 Pro likely still has an edge until official benchmarks say otherwise.
Do I need to change my prompts for Gemini 3.2?
Probably not significantly. It inherits the Gemini 3 prompting model: concise prompts, thinking_level for reasoning control, and no need for manual chain-of-thought scaffolding. Run your existing prompt suite and look for edge cases rather than rewriting from scratch.
What's the context window?
Consistent with the Gemini 3 series: 1 million token input, up to 64k tokens output. No leak data contradicts this, and it's the expected standard for all Gemini 3.x models.



