
Qwen3.7-Max and the 35-Hour Question: How Does It Stay Coherent?
One Task. Thirty-Five Hours. Zero Hand-Holding.
What if you gave an AI a low-level kernel optimization problem on a chip it had never seen before — no architecture references, no performance traces, just a mission and some tools — and let it operate uninterrupted for thirty-five hours?
That is what Alibaba's team reportedly did with Qwen3.7-Max, and the result has been generating serious conversation in the AI research community. Over the course of that run, the model made exactly 1,158 tool calls. It rewrote the same code segments from multiple angles, ran compile-profile-rewrite loops, identified bottlenecks without being told where to look, and ultimately delivered a 10× improvement in Triton operator performance on Alibaba's Pingtouge Zhenwu M890 processor — a domestic chip that has no public documentation.
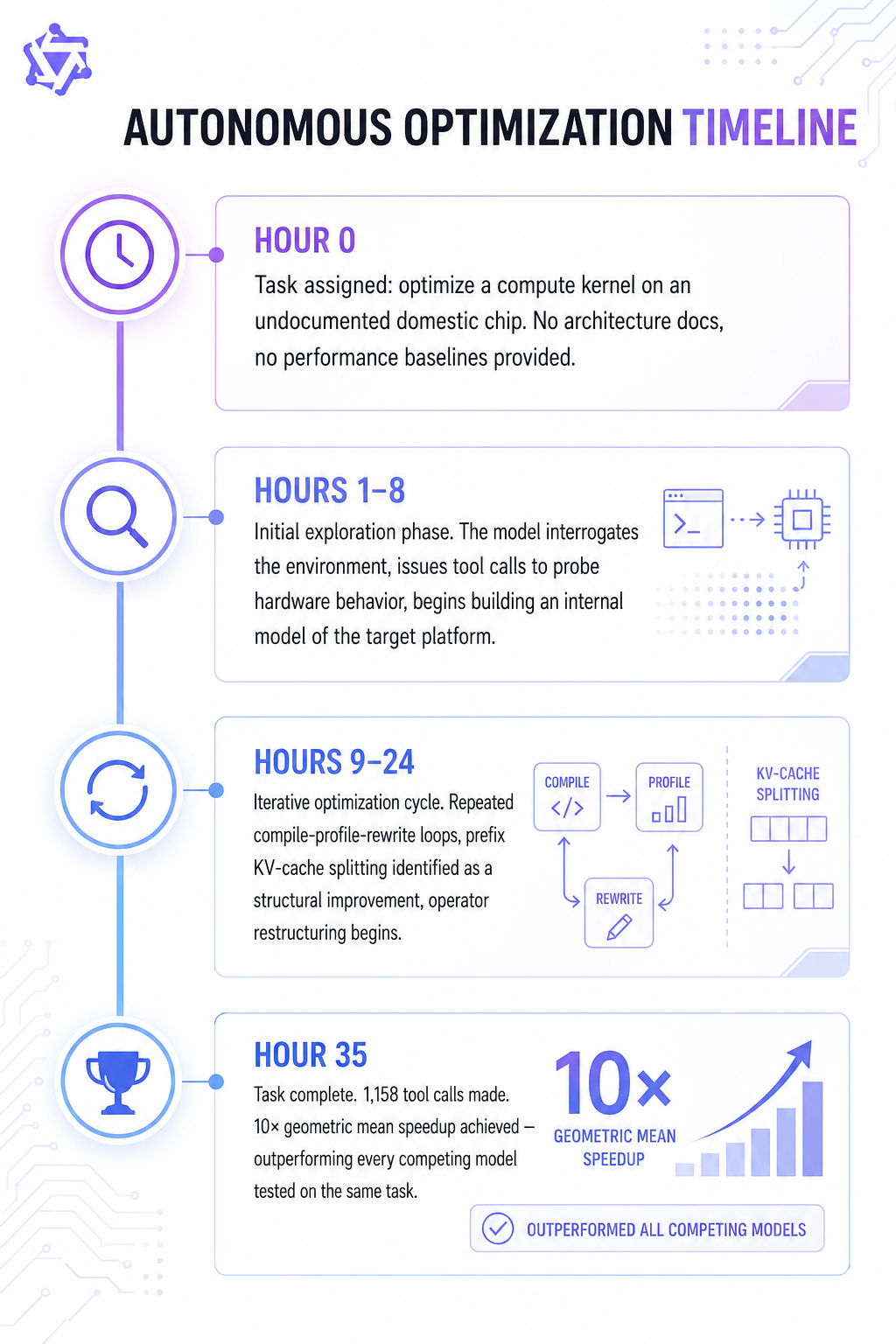
The central question worth sitting with is not the 10× speedup figure on its own — that's impressive but it's a product-specific result. What's genuinely unusual is the coherence story: how did the model maintain a consistent optimization strategy across 35 hours and more than a thousand tool calls without drifting, losing context, or getting stuck in unproductive loops? That question has real implications for anyone building AI agents that need to run unsupervised for extended periods.
A note on independent verification
The 35-hour run and 1,158 tool call figures are currently reported by Alibaba from internal testing. The benchmark is nontrivial to reproduce independently, it involves a partially undocumented domestic chip. Third-party verification is expected but will take time. The strategic implications don't depend on the exact numbers, but keep the sourcing context in mind.
Qwen3.7-Max Is Not a Chat Model With Agent Bolted On
Released on May 19, 2026, Qwen3.7-Max is Alibaba's latest proprietary flagship from the Qwen team. Unlike most models that get described as "agentic" because they support function calling, Qwen3.7-Max was designed from the ground up with sustained autonomous execution as the primary use case.
The model sits in the reasoning category, it uses extended chain-of-thought thinking before answering, which adds latency but significantly improves performance on complex multi-step problems. Artificial Analysis's independent benchmarking confirms it scores 57 on their Intelligence Index, placing it well above the median among comparable reasoning models in its price tier.
The core positioning
The model handles text input and produces text output only, it is not multimodal in this version. For vision tasks, the Qwen3.7-Plus-Preview is the relevant sibling. For the core agentic coding and reasoning use cases, Qwen3.7-Max is the flagship offering.
Strong Numbers Across the Board
The headline results are genuinely impressive across a broad range of evaluations. Qwen3.7-Max achieves scores that sit at or near the top of the current leaderboard across coding, agentic reasoning, formal math, and multilingual tasks.
On GPQA Diamond — the Graduate-level Physics, Chemistry, and Biology benchmark widely considered one of the hardest scientific reasoning tests — Qwen3.7-Max scores 92.4, edging out Claude Opus 4.6 (91.3) and DeepSeek V4 Pro (previously the leader in scientific reasoning). On Humanity's Last Exam, it scores 41.4 versus Opus-4.6's 40. On the 2026 HMMT competition math benchmark, it hits 97.1.
The verbosity observation
Artificial Analysis's evaluation introduced a useful data point: Qwen3.7-Max generated approximately 97 million output tokens to complete their Intelligence Index benchmark, compared to a median of roughly 24 million for comparable models. That's roughly four times as verbose.
This cuts both ways. Verbosity can indicate genuine extended reasoning, the model working through problems carefully rather than jumping to answers. But it also has practical cost and latency implications for developers. Artificial Analysis also noted that on their AA-Omniscience benchmark, the model's attempt rate dropped from 67.3% to 48.0%, it abstains more often and hallucinates less, but its raw factual recall appears to have narrowed. The tradeoff is deliberate: the model seems calibrated toward correctness over coverage, especially on hard questions it's uncertain about.
For agentic coding and autonomous task execution, that calibration is arguably the right one. An agent that says "I'm not certain" and loops back to gather more information is more useful than one that confidently proceeds with a wrong assumption. For rapid factual lookup or knowledge-retrieval tasks, the change is worth testing for before deploying.
Kernel Bench L3 deserves a specific mention because it connects directly to the 35-hour story. On this benchmark, which measures the model's ability to write CUDA kernels that outperform standard PyTorch implementations, Qwen3.7-Max achieves a 1.98× median speedup with a 96% win rate. That's the strongest score in this category among tested models and is a direct expression of the same capability demonstrated in the longer autonomous run.
The Coherence Mystery: What Keeps a 35-Hour Agent on Track?
Every developer who has worked with long-running AI agents knows the failure mode: the model starts strong, makes reasonable choices through the first dozen steps, and then quietly loses the thread. It forgets earlier constraints. It starts solving problems it already solved. It optimizes locally in ways that undo earlier global improvements. After a few hundred steps, the agent is working diligently but not coherently.
This is the hard problem that Qwen3.7-Max apparently addresses, and the how is worth thinking through carefully, because no one outside Alibaba has the full picture yet.
Plausible ingredients for long-horizon coherence
The 1M-token context window is a necessary but not sufficient condition. Having room to store the full task history doesn't automatically mean the model uses it well. Many models with long context windows still lose coherence because they attend unevenly across context, prioritizing recent tokens and underweighting early task specifications. The fact that Qwen3.7-Max maintains strategy suggests its attention mechanism handles long-range dependency better than previous generations, but we don't have confirmation of the specific architectural choice.
Training across diverse scaffolds may be the deeper story. Alibaba's own framing of the technical approach emphasizes something called decoupled training, a setup that separates the task itself, the runtime framework handling tool execution, and the validator assessing whether intermediate outputs are correct. If the model was trained to reason about tasks in a framework-agnostic way, that same decoupling may prevent it from overfitting to a specific execution pattern, which is exactly what you'd want for sustained runs where conditions slowly drift from the initial setup.
Better-designed validators may matter as much as the model itself. An agent that receives accurate feedback about whether each step improved the objective is much less likely to wander. The 35-hour run appears to have involved clear success criteria (kernel performance measurement was possible at every step), which gave the model reliable signal for its optimization loop. Task structure and validator design may explain part of the result independently of model architecture.
That framing from the Alibaba release documentation is the most interesting technical claim in the entire launch — and also the hardest to evaluate. Language generalization from diverse text is well-established; we understand the mechanism reasonably well. Whether the same scaling logic applies to agent scaffolds is an open question. If it does, the implication is that more diverse agentic training environments directly produce more robust autonomous execution, which would make the training pipeline design as important as architecture choices.
Real-World Use Cases: From Single Repositories to Multi-Agent Pipelines
Benchmark scores describe capability, but they don't always translate cleanly into where a model is genuinely useful in practice. Here's where Qwen3.7-Max appears to have a meaningful edge over previous generations.
How Qwen3.7-Max Compares on the Benchmarks That Matter for Agents
We track what actually impacts agent reliability in production: coding, agentic workflows, and reasoning. Head-to-head figures are drawn from the strongest publicly available results of competing frontier models.

The LM Arena neutral ranking gives additional signal: as of mid-May 2026, Qwen3.7-Max-Preview sits at #13 overall (Elo ~1,475), #7 in Math, #9 in Expert Prompts, #9 in Software/IT, and #10 in Coding. These are human-preference-based rankings from blind comparisons, so they capture something different from automated evaluations, they reflect whether actual users prefer its outputs in direct comparison.
Why This Actually Matters for Developers Building Production Agents
Most discussions of AI agent progress focus on benchmark numbers, which is fine but incomplete. The developer pain that actually limits real agent deployments is subtler: it's brittleness, tool drift, and framework overfitting.
Brittleness is when your agent works perfectly during testing and breaks in production because real tasks have slightly different structure than benchmark tasks. The cross-scaffold generalization that Qwen3.7-Max emphasizes directly addresses this, a model that has been trained against diverse frameworks is less likely to fail when your production environment differs from the evaluation setup.
Tool drift is when an agent gradually shifts its interpretation of tools over a long run — a function it was calling correctly at hour one is being called with subtly wrong parameters by hour six, usually because it's lost track of the tool's original definition amid a growing context. A 1M-token context window managed with proper attention mechanisms helps here, but the deeper fix is training the model to maintain accurate tool-use representations over time.
Framework overfitting is the most common problem in production agent deployments. Teams spend weeks getting a model working well with their specific scaffolding setup and then can't easily migrate to a different framework when requirements change. Qwen3.7-Max's documented approach of training with diverse scaffolds suggests it will be less susceptible to this, but it's worth running your own integration tests before committing to production use.
What to test before deploying
If the long-horizon coherence claims hold in independent testing, the practical implications are significant: AI agents for tasks like automated code review across large repositories, extended data analysis pipelines, or complex document generation workflows could become substantially more reliable. The current generation of agents tends to require human checkpoints every few hundred steps for anything mission-critical. A model that can genuinely maintain coherent strategy across thousands of steps changes the economics of what's worth automating.
The current preview status matters. Pricing, behavior, and benchmark scores can change before the stable release. The absence of open weights means the broader community can't probe the model independently yet, only through the API. That said, the API is live for testing, and early impressions from developers who have tried it on kernel optimization and repository-level coding tasks align with the headline claims.
The 35-Hour Question Remains Open and That's What Makes It Interesting
We don't have a clean, peer-reviewed explanation for how Qwen3.7-Max maintained coherent strategy across a 35-hour autonomous run. The decoupled training design is a plausible mechanism. The 1M-token context is a necessary enabler. The diverse scaffold training is likely a significant contributor. But the precise combination of factors, and whether they generalize to task types beyond well-scoped optimization loops, is still being worked out.
That's actually the most honest and interesting place to end up. If the claim were fully explained and independently verified, it would just be a feature. The fact that it raises genuine questions about training methodology, attention across long contexts, and the transferability of agentic capability is what makes it a research question worth following.
What we do know is that Qwen3.7-Max represents a real advancement in the benchmark categories that matter most for agent deployments, it introduces a training approach that explicitly targets the cross-scaffold generalization problem that plagues most production agent systems, and it provides a 1M-token context window on a reasoning model that scores at or near the top across coding, scientific reasoning, and multilingual tasks.
Whether it changes what's possible for your specific agent use case depends on your workload, and the best way to find out is to test it directly.
Ready to test long-horizon coherence for yourself?
Explore Qwen3.7-Max and build with it through AI/ML API, especially if you want to see what 35-hour agent stability looks like against your real workloads.



